

写在最前
如果你准备在本地跑一些大型模型,例如 Qwen 120B、DeepSeek-R1 671B(Q4量化)、GPT-OSS 120B 等,而且使用场景并发不高、甚至只有你自己一人使用,那么这台机器依然是 性价比非常不错 的选择——尽管价格本身并不便宜。
我在东京入手的 Mac Studio M3 Ultra(512GB RAM、2TB SSD),到手价也接近 人民币 8 万。但对于本地大模型开发和测试来说,它依然是一台很能打的设备。
AI 框架安装与大模型部署
这台机器上安装 vLLM 相当鸡肋,需要额外配置,例如禁用 CUDA 构建、设置 VLLM_BUILD_WITH_CUDA=0 使用 CPU 模式等等,体验并不好。
折腾了一圈后,我干脆选择了更简单的 Ollama 方案。
以下是我当前安装并测试过的模型列表:
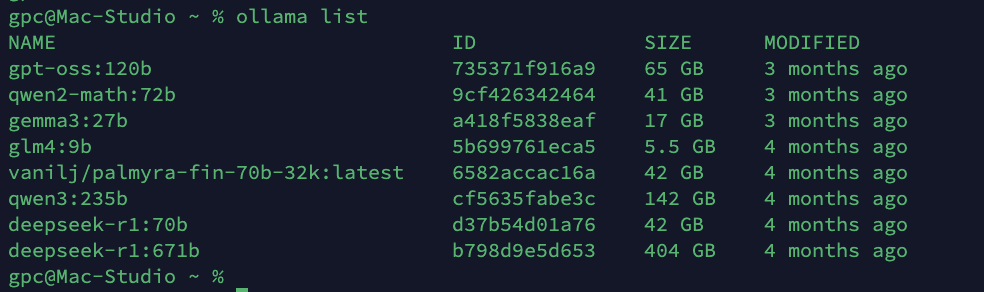
我安装的模型(精选说明)
-
gpt-oss:120b —— 使用最频繁的模型。智能程度与资源占用之间非常均衡,是目前最实用的一档。
-
qwen2-math:72b —— 偶尔用,用 /nothink 后容易“傻掉”,表现不稳定。
-
gemma3:27b / glm4 —— 已基本弃用。轻量但中文表现一般,有点“水土不服”。
-
palmyra-fin-70b-32k —— 金融方向模型,测试后效果一般,已弃用。
-
qwen3:235b —— 非常优秀,但运行时会吃掉约 140GB 内存(显存)。在 Mac 上跑起来非常慢,所以基本只用来偶尔验证。
-
deepseek-r1:70b —— 因为是好是坏,有的时候很智障,所以放弃了。
-
deepseek-r1:671b(Q4) —— 体验非常好,但运行就要 450GB 内存。只要再开点缓存或做点别的,就容易卡死。
-
deepseek V3 —— 实测完全扛不住,压力爆表,直接跑不动。
Token 输出速度
模型载入后,如果只是 单用户 + 普通文本生成,速度非常快,几乎秒出结果。
但需要注意:
-
仅限单模型、单用户场景
一旦并发增加 → 卡顿立刻出现
再增加一些负载 → 系统直接卡死
-
不确定是不是 Ollama 的问题:
模型频繁被重复加载调用时,幻觉率明显上升。
即使调了温度等参数,问题依旧存在。
发热表现
不得不说,Mac Studio 的散热表现相当优秀。
即使长时间满载运行:
-
机身温度仍然可控
-
不烫手
-
只有轻微发热
这是苹果机型比较让人安心的一部分。


暂无评论内容